

WTF: Open Source Web Testing Framework
Boldare’s Web Testing Framework is a framework designed for the automation of End-To-End (E2E) tests of web applications. It was created as part of a company initiative called “10% of time for open-source” and it was released under the terms of MIT license.

Table of contents
One of the goals of creating this framework was to simplify writing tests that are useful both for development team and for business purposes. For this reason, the test execution logs are quite complex. Reports may be useful for business users thanks to Gherkin scenarios, which use natural language to describe the performed tests, and screenshots to visualize the errors.
Dev teams will make use of the low-level logs, such as requests history (HAR) collected by proxy or browser console logs. Framework methods are high-level and have built-in waits, which facilitates writing tests significantly. The ease of test-writing was itself tested during in-house training for our company interns, who were able to learn how to write tests in quite a short time despite being previously unfamiliar with the technology.
Boldare’s Web Testing Framework is available via GitHub and NPM.
Main goals
Language
The framework was written in JavaScript. There were several reasons for that choice, the most important being JavaScript’s popularity when it comes to web apps. When tests are written in a language commonly used by developers, there’s no problem with finding people who could run a code review of the tests. Besides, code reviews carried out by someone specializing in a given technology are the most valuable – they are more than mere checking of general assumptions. In case of Python or Java that could have been problematic.
Selenium WebDriver
Selenium WebDriver is probably the most frequently used tool for automating E2E web apps tests, directly or indirectly. Its bindings are also available for JavaScript (although they’re simplified in comparison with PHP, Python, or Java). So, Selenium WebDriver was also used as a base for the Boldare Web Testing Framework.
Gherkin – useful for business goals
E2E tests should be useful not only from the dev team’s perspective. Business clients are also important users of tests, which should be easily understood by non-technical persons. That’s why Gherkin was used as the BDD layer. When properly used, the overhead on the Gherkin layer is minimal, and Gherkin itself has a lot of advantages for dev teams: it generates clear test reports, makes it easier to create bug reports, etc.
Logs
The main purpose of E2E tests is to verify if the app is working correctly. However, it’s also crucial to quickly identify errors in the case of a red test. In such situations, each detail that can help to reproduce the error or fix it may come in handy.
- Gherkin scenarios are the first level of logs. In fact they’re steps helping reproduce the bug: apart from being used in bug reports, they will be understandable by clients.
- Screenshots are another frequently used test output – thanks to them, you can see what the tested app looks like in the moment of failure, from a high-level point of view.
- For developers, HAR is definitely a useful log. It can be used to track particular requests, which can be very helpful in identifying problems. Proxy is used to collect them, and HAR files are saved for every scenario.
- The browser console logs can be of use mainly for front-end developers.
- The Selenium driver log can be a great help for QAs, mainly while writing new tests.
- The framework log supplements the logs above. It can be general – in the case of a method failure – or specific, providing information that helps track the functioning of the tests.
- Other useful logs (without support implemented in framework yet) include web server logs. Another source of logs can be tools, which are specific to the technology used in the project: in the case of the PHP and Symfony back-end, these would be Symfony Profiler logs.
Easy and quick test implementation
Commercial project tests are always limited by budget – you can virtually never test the app as vigilantly as you would like to. Still, the framework you use has a significant impact on the pace of test writing.
- High-level methods available in the framework facilitate test implementation and also speed it up. The availability of these high-level methods does not limit the user – low-level Selenium WebDriver methods are also available and can be used if necessary.
- Framework methods have built-in waits, which makes it much simpler to use them. The user retains the control over them – the default values of the configuration file config.json are normally used, but you can choose a non-standard value when calling particular methods.
Stability
Dev teams cannot trust tests if the results do not recur in a given version of the app or when some tests are randomly “red”. The most frequent causes of non-stable tests that I’ve encountered are incorrectly used waits and application state changes during the execution of an action. The built-in waits in our framework methods have another good point – apart from the ease of use and quickness of test writing – they improve test stability.
Headless
E2E tests are often run on headless servers. The frequently recommended headless browsers, e.g. PhantomJS, do not correspond with real browsers. PhantomJS uses a forked version of the QtWebKit engine from the Qt library, which is considerably different even from the WebKit engine used in Safari. E2E tests run on such browsers will not guarantee the proper functioning of the app on the real browsers.
One option of running headless tests on a real browser is to use Xvfb (X virtual framebuffer), a Linux tool that enables you to create a virtual screen within which a real browser (like Chrome or Firefox) can be started. If a browser is not available for Linux, you can use Remote Driver and connect to a virtual machine or a cloud service offering browsers for test execution.
Methods
The framework gives access to methods which can be generally divided into actions, validators, and “other”.
Actions are methods allowing the use of particular tasks in the browser, e.g. clicking. Validators verify the effect of the performed actions.
Both actions and validators are performed in the context of page elements: for example, you can click on an element or check if it is visible. The elements are identified by XPath selctors.
A complete list of the available methods can be found in the manual at GitHub; below, you’ll find a few examples.
Actions
- click(xpath, customTimeout)
Thanks to the click method, you can click on an element identified by XPath referenced by an xpath parameter.
customTimeout is an optional parameter serving to define the maximum time for an action. If it’s not set, the default value from the framework’s configuration file will be used. - loadPage(url, customTimeout)
loadPage opens a page given as a url argument.
The customTimeout parameter, just like in the click method, is optional. - Main actions:
fillInInput
setCheckboxValue – defining the checkbox value – true / false
setFileInputValue
sleep – static sleep
cleanBrowserState – cleaning browser state (cookies, localStorage, sessionStorage, console log)
Validators
- Get and Validate
In the framework, get methods return a value, e.g. the number of elements on the page, the text on the elements, etc. Validate methods serve to verify whether the number of elements is correct or whether the text is right.
The main difference is that get shows the current status, and validate checks that a given value agrees with the expected value before the timeout. This is especially important in the case of dynamic pages where the value can change. Thanks to validate, logic can also be transferred to a lower level – instead of getting the values during the tests to check if they’re correct, the validator can be used. The logic can be transferred even lower: to XPath, which enables you to verify several values at the same time, as can be seen in the following example – validateElementDisplayed. - validateElementDisplayed(xpath, customTimeout)
The validateElementDisplayed method validates the visibility of the XPath-identified object. It can be a simple element or an extended XPath like the one presented below, validating two values simultaneously. XPath finds the div element containing two child elements – span – with specific values.web testing framework

- Main methods
getCurrentUrl, validateUrl, validateUrlByRegex
validatePageReadyState
validateElementDisplayed / NotDisplayed
validateElementVisible / NotVisible
validateElementsDisplayed / NotDisplayed
getCheckboxValue, validateCheckboxValue
getElementsNumber
getElementText, validateElementText
Other methods
Other methods are not directly related to the actions performed on the page, but they may prove useful while writing tests. These are, for example, loggers and methods allowing the taking of screenshots or loading the current time.
Configuration
To configure the framework, you can use the config.json file. It’s one of the framework’s requirements, so it should be visible in the main project directory. It contains the most important settings of the framework – from the most basic, like the Selenium Server URL, to more advanced ones, like the level of proxy logging or Selenium Server polling delay. The picture presents a sample configuration; you’ll find more detailed information in the GitHub documentation.

How do you make a test?
The framework doesn’t impose any particular way of writing a test, apart from the fact that Gherkin scenarios must be on the top. Below, you’ll see one of the possibilities.
Gherkin
In the features directory, there are .feature files containing Gherkin scenarios for particular functionalities. In the example below, you can see a sample scenario verifying the correctness of an online shop functionality – buying a product.
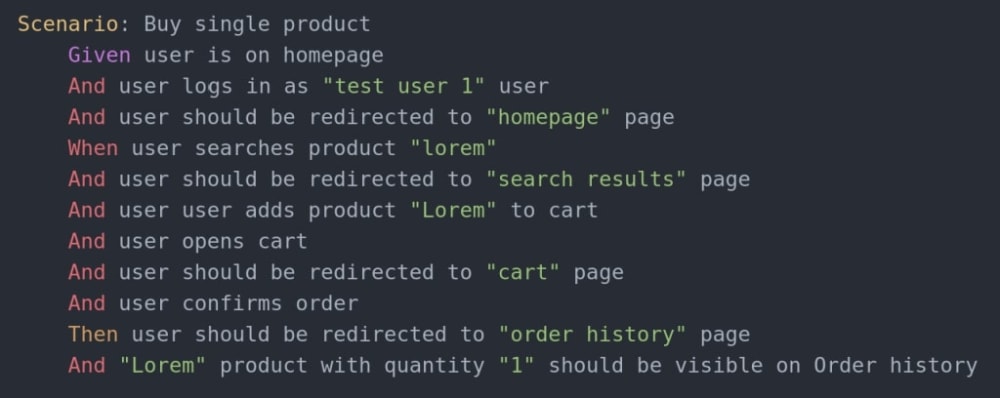
The steps are high-level, as they describe whole actions, for instance, adding a product to the cart. In this way, they are both understandable by business users and useful for dev team, and at the same time they reduce the overhead resulting from writing scenarios. Additionally, any possible changes in the app will not result in the need to rewrite a big part of the scenario – some modifications “below” should be enough.
In most cases, test data are not directly placed in Gherkin – there is a clear, separate name which allows to get them from test-data file.
Step->Context
The example of logging in will show you how individual steps are mapped with corresponding actions.

Context methods are automatically generated by Cucumber – you just need to name the parameters used (in this case: userName) and call the adequate method from the proper page.

In this situation, the log-in form undergoing the test is on the home page – therefore, the logIn method used to log in is located in HomePage (the home page is really simplified so there’s no need for a separate Page, such as LoginPage). It only serves to execute the appropriate method and pass the parameter: userName (“test user 1”). The correct logic is in the Page method.
Page

The logIn method visible above fills in the login and password fields and clicks on “log in” button. Test data (username or password) are taken from the test-data file by means of the getUserData method. The user in test data is identified through the username provided in the userName parameter.
Test data
Test data are located in testData.js. This can be, for example, JSON containing all the necessary values. User data can be named, e.g. userData. In the log-in scenario, the username and password would be sufficient. In other scenarios, though, other details might be necessary, such as the e-mail address.
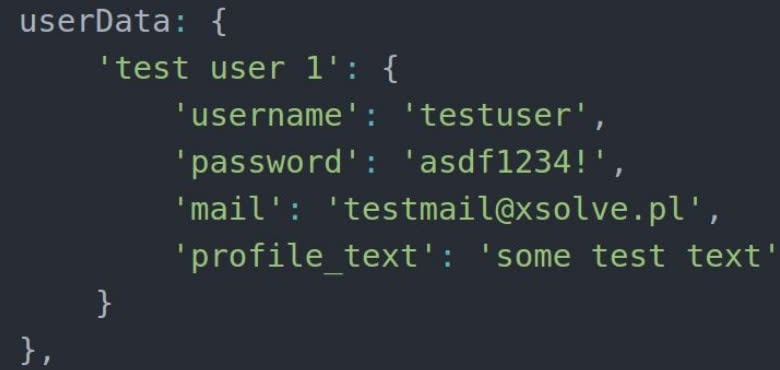
The getUserData method presented in the example only returns values for a particular user, improving readability when compared to direct getting of the value. It might happen, though, that the data must be processed in some way.

Open source
The Boldare Web Testing Framework is a young project – there are many functionalities to be added and numerous ways of improving the existing ones. Feel free to take part in the process of developing the framework, both in the form of PRs and through suggestions of what could be changed or made better.
You can access the framework via GitHub and NPM.
Share this article:



