

How RAG improves LLM accuracy: A technical overview
Weekly AI Bites is where we share what actually happens when AI meets real products. This article comes straight from our internal discussions, experiments, and production challenges — specifically around Retrieval-Augmented Generation (RAG) and how we use it in practice.
RAG is one of those concepts that sounds simple in theory, but quickly becomes complex once you start working with real data, imperfect documents, and real user questions. In this bite, we break down how RAG really works, why embeddings and chunking matter more than most teams expect, and what we’ve learned while building and evaluating RAG systems for internal tools and client projects.
If you’re curious how LLMs can go beyond their training data, how to reduce hallucinations, and what actually improves answer quality in production, this article is for you.\ Every Weekly AI Bite reflects what we’re testing right now — not what’s trending, but what’s working. Catch a new bite every Monday on Boldare’s channels.

Table of contents
Retrieval-Augmented Generation (RAG) addresses one of the core limitations of Large Language Models: they only know what they were trained on. RAG extends an LLM’s capabilities by dynamically injecting external knowledgeinto its context, pulling data from sources such as databases, internal documents, or web content in multiple formats. If you remember the original Matrix movie, RAG works like uploading Kung Fu skills directly into Neo’s mind — the model suddenly knows something it didn’t before.
Imagine you possess confidential Kung Fu manuals that were never part of any LLM’s training data. When a user asks, “What’s the correct stance for the Flying Crane kick?”, a RAG system searches those documents, identifies the most relevant passages, and supplies them to the LLM. Instead of passing the entire document — which would exceed the context window — RAG selects only the most meaningful fragments. The model then generates an answer grounded in those retrieved sources, rather than guessing or hallucinating based on prior training alone.
This article is intended to give software engineers a practical understanding of RAG, whether they’re building an internal knowledge base, a Q&A system, or a legal assistant. Relying solely on an LLM’s internal knowledge is often insufficient due to training cut-off dates and incomplete internet coverage. Even when using managed RAG solutions instead of building your own pipeline, having a high-level conceptual understanding remains extremely valuable.
Embeddings and indexing
Why not just rely on grep or traditional full-text search? Because users rarely phrase questions using the exact wording found in documents. Embeddings transform text into high-dimensional vectors, where semantically related concepts cluster together. Much like Neo perceiving the Matrix as streams of code, embeddings convert language into numerical representations that capture meaning. For example, “Morpheus” and “mentor” may appear close together in vector space, while “Agent Smith” would be far away — distance reflects conceptual similarity. These vectors must be stored somewhere, which is where vector databases come into play.
Indexing involves loading documents from various formats, breaking them into smaller chunks, and converting those chunks into embeddings. Chunking is essential due to LLM context limits, and smaller chunks generally improve retrieval accuracy. There are multiple chunking strategies, including separator-based, semantic, or structure-aware approaches. In practice, parsing complex formats — such as PDFs with tables or images — is often the hardest part and has a significant impact on quality. Adding metadata like section headers or file names further improves contextual grounding. Whenever documents change, this indexing process must be repeated.
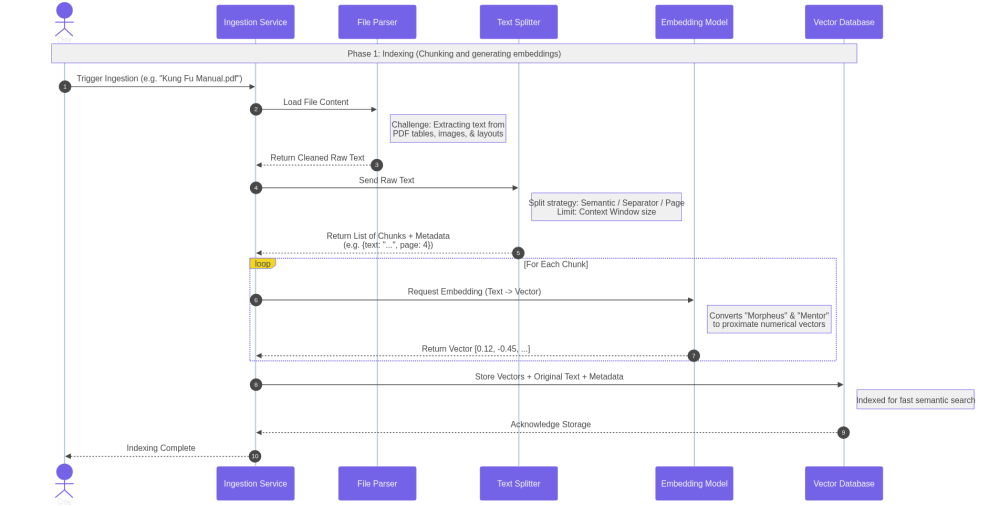
Querying
Once embeddings are indexed, the system can handle user queries. The user’s question is converted into an embedding and matched against the vector database to find semantically similar chunks. These retrieved passages — optionally filtered or refined — are combined with the original query and sent to the LLM, which generates the final response.
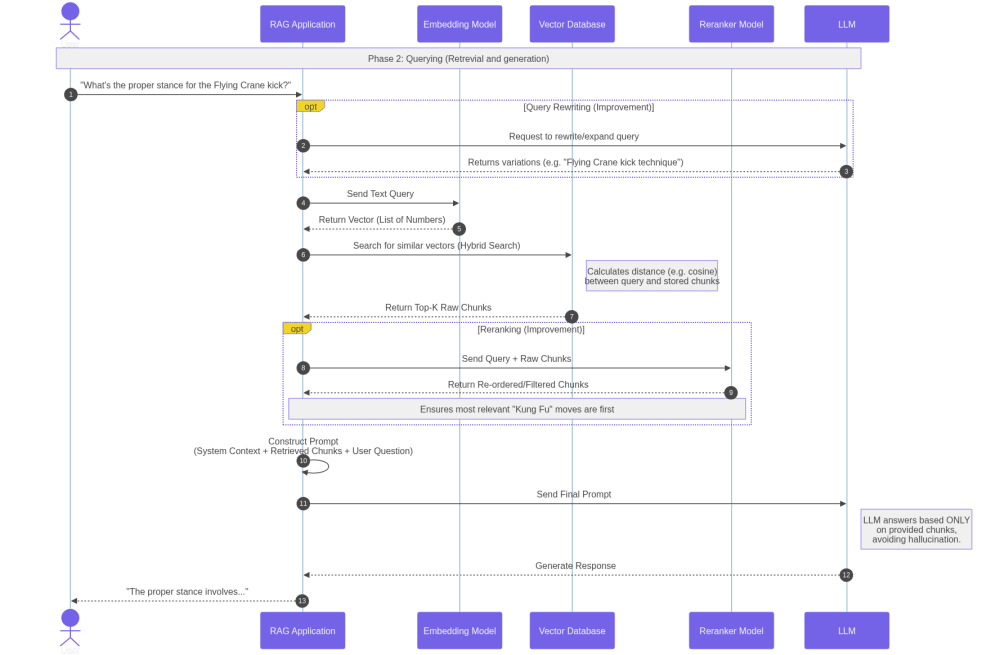
Choosing a tech stack
Tool selection should be driven by practicality — often the best option is what already fits into your existing stack. For local development and experimentation, two technologies stand out. PostgreSQL with the pgvector extension enables embedding storage and similarity search in a familiar database environment. Ollama allows running smaller LLMs locally, both for embeddings and text generation. From there, development can start with a provider SDK and gradually evolve as requirements grow.
Improving RAG systems
Before optimizing anything, define clear metrics and evaluation criteria — essentially unit tests for LLM systems. Start by building a test dataset that reflects real user queries, including summaries, explanations, definitions, and reasoning tasks. The system should also gracefully handle situations where it does not know the answer. Like traditional unit tests, these evaluations act as a safety net, ensuring changes can be deployed with confidence. New edge cases should continuously be added to the evaluation suite.
Evaluation can be manual or automated using an LLM-as-a-judge approach, where another model scores the output. Key metrics to track include correctness, faithfulness to retrieved context, completeness, tone and conciseness, retrieval precision, and retrieval recall.
Once performance can be measured, improvements may include refining chunk sizes, removing duplication, adding overlap between chunks, improving prompt design, rewriting queries, reranking results, or combining vector search with traditional keyword search. Additional safeguards include input and output sanitization to prevent prompt injection, monitoring latency and cost, and tracking failed retrievals. Advanced approaches like GraphRAG or HyDE exist but fall outside this article’s scope.
Agentic RAG
A more advanced evolution is Agentic RAG, which introduces greater flexibility. Here, the LLM first interprets the user query and decides whether it can answer directly, needs clarification, or should call tools to fetch more information. The agent may invoke the RAG pipeline multiple times before delivering a final response — adaptive, autonomous, and iterative, much like Agent Smith in the Matrix.
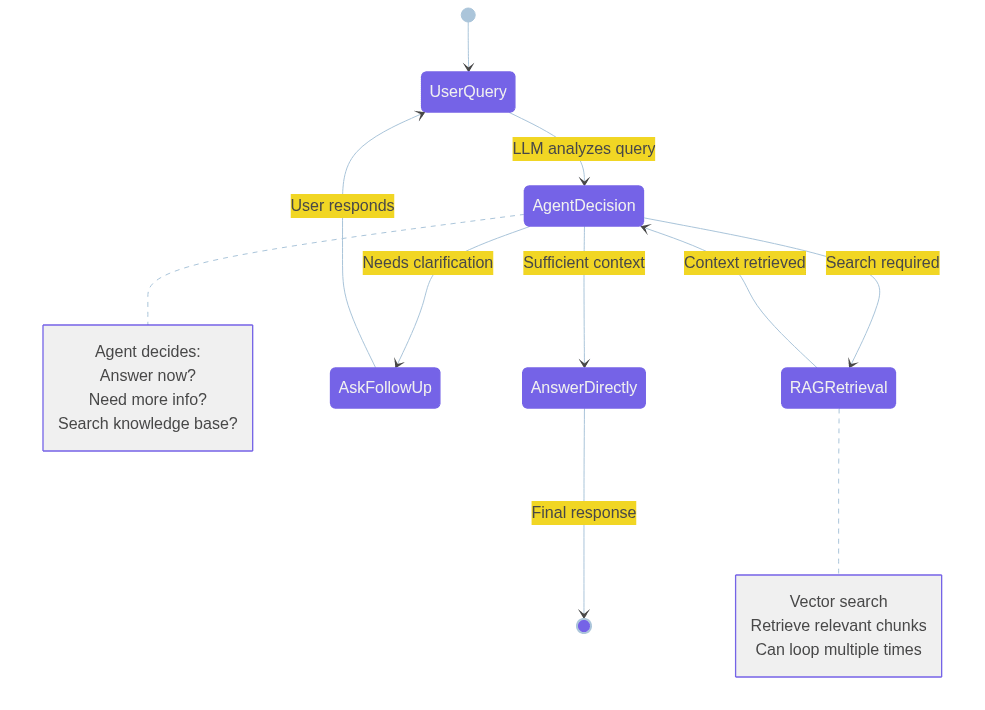
Key takeaway
Before choosing a vector database or architecture, focus on the problem RAG is meant to solve. Ask yourself which workflows you want to improve, how success will be measured, whether your data is clean, how answer correctness will be verified, and how you’ll track performance changes over time. Also consider how indexed content will stay up to date.
LLMs trust the context you provide. Make sure it’s the red pill of high-quality data, not the blue pill of hallucinations and confusion.
Share this article:





